Questo sito utilizza cookie per raccogliere dati statistici.
Privacy Policy
# Rappresentazione dei Dati di Testo in Informatica
In informatica, i dati di testo vengono memorizzati nei computer utilizzando sequenze di numeri binari (0 e 1), che i computer sono in grado di comprendere e gestire. Poiché sappiamo già come convertire un numero intero in binario, possiamo rappresentare qualsiasi valore in forma binaria se troviamo un modo per associare ogni valore specifico (come un carattere di testo) a un numero intero.
## La Tabella ASCII
Uno dei primi metodi di codifica per rappresentare il testo è la tabella **ASCII** (American Standard Code for Information Interchange). ASCII è uno standard che assegna a ogni carattere un numero intero tra 0 e 127, utilizzando 7 bit (128 combinazioni). Questa associazione permette di convertire ogni carattere in una sequenza di 0 e 1.
- **Esempio**: il carattere "A" ha il valore numerico 65 in ASCII, che in binario diventa `01000001`.
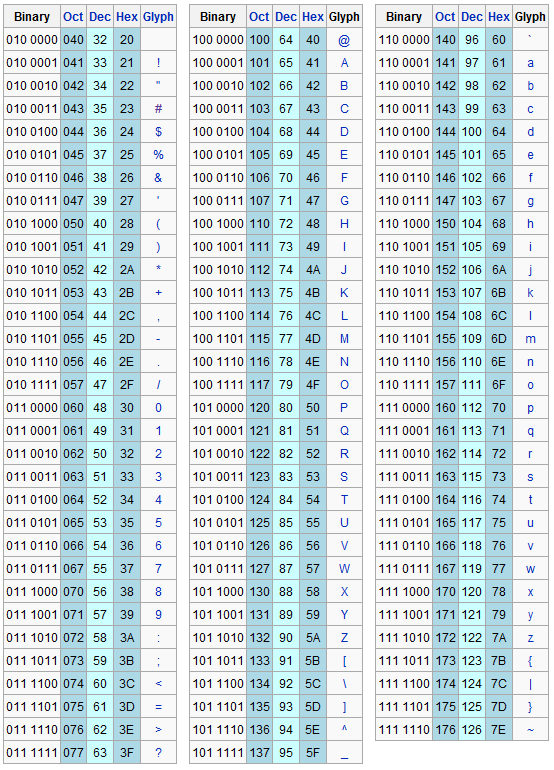
### Struttura della tabella ASCII
- **Caratteri di controllo** (da 0 a 31): rappresentano comandi come `ESC` o `DEL`, usati per funzioni di controllo nei sistemi.
- **Caratteri stampabili** (da 32 a 126): comprendono lettere, numeri, segni di punteggiatura e simboli.
- **Estensione ASCII** (da 128 a 255): una versione ampliata, non standard, che include altri simboli per supportare più lingue, ma non è parte della tabella ASCII originale.
Poiché ASCII rappresenta solo i caratteri della lingua inglese, non riesce a includere adeguatamente altre lingue e simboli speciali.
## I Limiti di ASCII e l’Introduzione di Unicode
Con la diffusione dell’informatica a livello globale, è diventato necessario un sistema di codifica più completo per rappresentare caratteri di lingue diverse, come lettere accentate, simboli speciali e ideogrammi cinesi. A questo scopo è stato creato **Unicode**, uno standard in grado di rappresentare praticamente ogni carattere usato nel mondo.
Unicode è retrocompatibile con ASCII, permettendo così di rappresentare facilmente anche i caratteri ASCII. Per essere flessibile rispetto ai caratteri, Unicode supporta diverse modalità di codifica:
- **UTF-8**: utilizza da 1 a 4 byte per ogni carattere. È compatibile con ASCII (i caratteri ASCII usano 1 byte) ed è la codifica più diffusa sul web.
- **UTF-16**: usa 2 o 4 byte e viene utilizzato principalmente per testi contenenti caratteri di lingue non latine.
- **UTF-32**: utilizza 4 byte per ogni carattere, ma occupa molto spazio e quindi è usato raramente.
### Come si Rappresentano i Caratteri Unicode
In **UTF-8**, il sistema utilizza i primi bit di ogni byte per identificare la lunghezza del carattere, il che permette di capire immediatamente se si tratta di un carattere ASCII semplice (1 byte) o di un carattere più complesso che richiede più byte.
| Primi bit del byte | Lunghezza del carattere |
|--------------------|-------------------------|
| 0xxxxxxx | 1 byte (ASCII) |
| 110xxxxx | 2 byte |
| 1110xxxx | 3 byte |
| 11110xxx | 4 byte |
- Se il primo bit è 0 (come in `01000001` per "A"), il computer sa che è un carattere ASCII e che deve utilizzare solo 1 byte.
- Se il byte inizia con `110`, allora il carattere richiede 2 byte.
- Se il byte inizia con `1110`, significa che il carattere richiede 3 byte, e con `11110` il carattere richiede 4 byte.
### Esempio di Rappresentazione del Testo in UTF-8
Per esempio, la parola “Caffè” in UTF-8 è rappresentata così:
- "C" = `01000011` (1 byte)
- "a" = `01100001` (1 byte)
- "f" = `01100110` (1 byte)
- "f" = `01100110` (1 byte)
- "è" = `11000011 10101000` (2 byte, poiché è un carattere accentato)
Il carattere "è" inizia con `110`, quindi il computer sa che deve usare anche il byte successivo per completare la rappresentazione del carattere. In totale, la parola “Caffè” richiede 6 byte.
### Vantaggi di Unicode rispetto ad ASCII
- Unicode permette di rappresentare più di un milione di caratteri di quasi tutte le lingue del mondo.
- Include simboli tecnici, matematici, emoticon e altri caratteri speciali.
---
## Riassunto e Conclusioni
1. **ASCII**: una codifica a 7 bit che rappresenta solo i caratteri della lingua inglese.
2. **Unicode**: uno standard in grado di rappresentare caratteri di tutte le lingue del mondo.
- **UTF-8**: compatibile con ASCII, utilizza da 1 a 4 byte e oggi è la codifica più comune.
- **UTF-16**: utilizza 2 o 4 byte, meno diffuso sul web.
- **UTF-32**: utilizza 4 byte, ma è dispendioso in termini di spazio, quindi viene usato raramente.
UTF-8 è oggi lo standard di codifica per la maggior parte delle applicazioni, poiché permette di rappresentare efficientemente i dati di testo in molte lingue e di gestire una varietà di simboli e caratteri, superando così i limiti di ASCII.