Questo sito utilizza cookie per raccogliere dati statistici.
Privacy Policy
# Database - Progettazione Logica
Dopo la fase di progettazione concettuale, nello sviluppo di una base di dati si passa al livello logico
Tra i diversi modelli a livello logico sarà affrontato il modello relazionale dei dati, proposto nel 1970 da Edgar F. Codd. In questo modello una base di dati è vista come un insieme di tabelle sulle quali possono essere eseguite opportune operazioni.
## Relazioni tra insiemi
Il modello relazionale si chiama così perché è fondato sul concetto matematico di relazione tra insiemi di oggetti.
Si dice **prodotto cartesiano** di A1 per A2, e si indica con A1 × A2, l’insieme delle coppie (x,y) dove x appartiene ad A1 e y appartiene ad A2.
Si dice **relazione** su due insiemi A1 e A2 un qualsiasi sottoinsieme R del prodotto cartesiano dei due insiemi A1 e A2:
R(A1, A2) ⊆ A1 ×A2
Il modello relazionale si basa su alcuni concetti tipicamente matematici e attribuisce grande importanza all’uso rigoroso del **linguaggio** **matematico**, con due obiettivi:
* utilizzare un linguaggio conosciuto a livello universale;
* eliminare i problemi di ambiguità nella terminologia e nella simbologia.
<ex>
Si considerino i due insiemi *A1 \= {4, 9, 16}* e *A2 \= {2, 3}.*
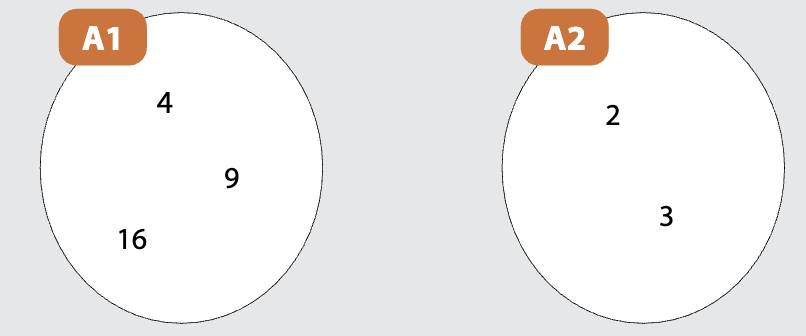
Il prodotto cartesiano di A1 per A2 è:
*A1×A2 = { (4,2), (4,3), (9,2), (9,3), (16,2), (16,3) }*
La seguente figura visualizza il **prodotto cartesiano** di A1 per A2 e la **relazione** Q sui due insiemi.
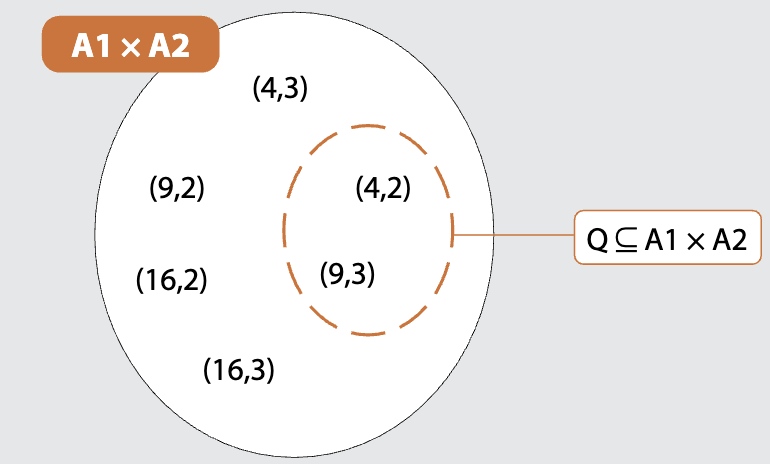
Alcune coppie del prodotto cartesiano sembrano essere più significative di altre. È il caso del sottoinsieme Q, composto dalle coppie di valori (x, y) dove x è il quadrato di y. Q può essere descritto da “x è il quadrato di y” ed esprime la relazione “essere il quadrato di” esistente tra elementi di A1 e A2
</ex>
## Relazioni come Tabelle
Sia *A1xA2* sia la relazione tra i due insiemi possono essere rappresentati con **tabelle**. Ogni tabella è composta da tante righe quanti sono gli elementi del prodotto cartesiano oppure della relazione e da due colonne per rappresentare ordinatamente il valore del primo e del secondo elemento delle coppie (x,y). Per evitare ambiguità si può porre in testa a ogni colonna il nome dell’insieme considerato
<ex>
Considerando la relazione Q dell’esempio precedente, indicata con il nome ***QuadratoDi***, si possono ricavare le seguenti tabelle:
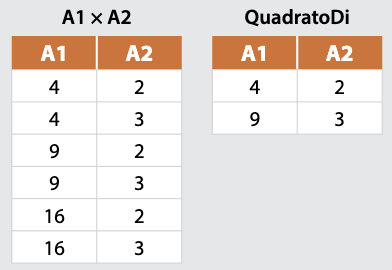
</ex>
<ex>
Si prendano adesso in considerazione, in riferimento alle automobili, gli insiemi *Modello* e *Costruttore*, così definiti:
*Modello \= { City1, Sport2.0, SUV3, SW1.5 }, Costruttore \= { Gamma, Omega }*
Il prodotto cartesiano *Modello×Costruttore* è formato dalle 8 coppie ottenute componendo un elemento di Modello con un elemento di Costruttore in tutti i modi possibili.Si consideri ora il sottoinsieme di *Modello×Costruttore* formato dai quattro elementi:
*{ (SUV3, Gamma), (SW1.5, Gamma), (City1, Omega), (Sport2.0, Omega) }*
che si indicano, in modo significativo, con il nome *ProdottoDa*.
Il prodotto cartesiano ***Modello×Costruttore*** e la relazione ***ProdottoDa*** possono essere rappresentati con le seguenti tabelle.
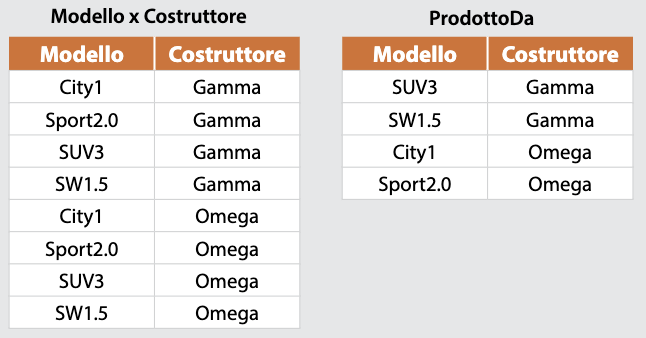
Il prodotto cartesiano *Modello×Costruttore* non contiene informazioni utili, mentre la relazione *ProdottoDa* è significativa e permette di conoscere il costruttore delle vetture elencate.
</ex>
È possibile a questo punto specificare ulteriormente la definizione di relazione dal punto di vista matematico.
Una **relazione** su n insiemi *A1, A2, ..., An* è un sottoinsieme dell’insieme di tutte le *n*\-uple *a1, a2, ..., an* che si possono costruire prendendo nell’ordine un elemento *a1* dal primo insieme *A1*, un elemento *a2* dal secondo insieme *A2* ecc.
Una relazione con *n* colonne si indica come una relazione di **grado** n, il nome con il quale si identifica una colonna si chiama **attributo**, l’insieme dei valori che possono essere assunti da un attributo definisce il **dominio** di quell attributo e il numero delle *n*\-uple che compongono la tabella (indicate anche con il termine **tuple**) si chiama **cardinalità** della relazione.
<ex>
La relazione **ProdottoDa** dell’esempio precedente è una relazione di grado 2 e cardinalità 4\. La coppia (*City1, Omega*) è una delle 4 tuple della relazione. La relazione ha due attributi (*Modello e Costruttore*) che assumono valori nei due domini, formati, rispettivamente, dall’insieme dei modelli di automobili prodotte e dall’insieme dei costruttori di automobili.
</ex>
In sintesi, dunque, la relazione è rappresentata con una tabella avente tante **colonne** quanti sono gli attributi (grado della relazione) e tante **righe** quante sono le *n*\-uple (cardinalità della relazione).
I nomi degli attributi sono i nomi delle colonne; i valori che compaiono in una colonna sono omogenei tra loro, cioè appartengono a uno stesso dominio. La relazione è quindi una collezione di *n*\-uple, ciascuna delle quali contiene i valori di un numero prefissato di colonne.
La relazione modella un’**entità**, ogni *n*\-upla rappresenta un’**istanza** dell’entità, le colonne contengono i valori assunti dagli **attributi** dell’entità.
<im>
Possiamo notare come il termine ***relazione*** appena introdotto sia differente dal termine *relazione* utilizzato finora a livello concettuale.
La relazione concettuale è un **legame** che stabilisce un’interazione tra le entità.
Per relazione all’interno di uno schema relazionale si intende essenzialmente una **tabella**. È composta da righe e colonne, dove ogni riga (o tupla) rappresenta un insieme di dati correlati e ogni colonna rappresenta un attributo di quei dati.
</im>
La **chiave primaria** della relazione è un attributo (o una combinazione minimale di attributi) che identifica univocamente le *n*-uple all’interno della relazione, cioè ogni riga della tabella possiede valori diversi per l’attributo (o gli attributi) chiave.
Per questo motivo il modello relazionale fissa una regola di integrità sui dati, detta **integrità sull’entità**, secondo la quale la chiave primaria non può avere valore nullo.
## Schema delle tabelle nel database relazionale
Seguendo una notazione ormai consolidata, si rappresenta una tabella mediante il suo **schema** indicando tra parentesi, dopo il nome della relazione (o tabella), i nomi degli attributi (o campi) separati dalla virgola e sottolineando gli attributi chiave.
<ex>
***Automobili** (Modello, Costruttore, Segmento, Porte, Posti)*
</ex>
Lo **schema di un database relazionale** è definito dallo schema delle tabelle che lo compongono.
<ex>
Il database per le vendite di prodotti che appartengono a diversi reparti di un negozio ha lo schema:
**Reparti** *(CodReparto, NomeReparto)*
***Prodot**ti (CodProdotto, Descrizione, Prezzo, CodReparto)*
***Vendite** (Numero, Data, Quantità, CodProdotto)*
Le tre tabelle sono popolate con alcuni dati di esempio.
**Reparti**

**Prodotti**
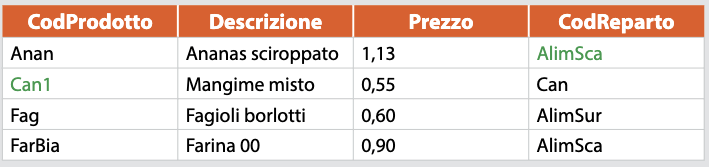
**Vendite**
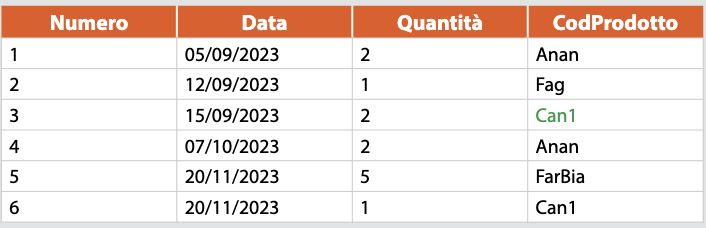
Le tabelle mostrano com’è rappresentata la relazione tra *Prodotti* e *Reparti* e tra *Vendite* e *Prodotti*:
- l’informazione sul reparto dove è venduto il prodotto `Ananas sciroppato` è data dal valore del campo *CodReparto* della tabella *Prodotti*;
- analogamente è possibile riconoscere il nome del prodotto oggetto di una vendita tramite il valore del campo *CodProdotto* di *Vendite*.
I campi *CodProdotto* di *Vendite* e *CodReparto* di *Prodotti* prendono il nome di **chiavi esterne**. Inoltre, considerando la tabella *Vendite* e la riga con Numero = 5, si può dire che il campo di nome *Quantità* vale 5.
</ex>
Il modello relazionale è un modello fondato sui valori. Ogni dato elementare contenuto nel database è accessibile mediante nome della tabella, nome e valore della chiave, nome della colonna con il dato.
I **requisiti** **fondamentali** delle tabelle di un database relazionale sono i seguenti:
* tutte le righe della tabella contengono lo **stesso numero di colonne**, corrispondenti agli attributi;
* gli attributi rappresentano **informazioni elementari** (o **atomiche**), non scomponibili ulteriormente, cioè non ci sono campi di gruppo che contengono per ogni riga un insieme di valori anziché un solo valore;
* i valori assunti da un campo appartengono al dominio dei valori possibili per quel campo e quindi sono **valori** **omogenei** tra loro, cioè sono dello stesso tipo;
* in una relazione (tabella) ogni riga è diversa da tutte le altre, cioè non ci possono essere due righe con gli stessi valori dei campi. Questo significa che esiste un attributo (o una combinazione di più attributi) che identifica univocamente la *n*-upla, e che assume perciò la funzione di **chiave primaria** della relazione (tabella);
* le *n*-uple compaiono nella tabella secondo un ordine **non prefissato**, cioè non è rilevante il criterio con il quale le righe sono sistemate nella tabella
# Derivazione delle relazioni dal modello E/R
Dal modello concettuale è possibile ottenere il modello logico dei dati: in altre parole si può **definire la struttura degli archivi** adatti per organizzare i dati. Nel caso del modello relazionale le tabelle, che costituiscono il livello logico, sono ricavate dal modello E/R mediante alcune semplici **regole di derivazione**.
* Ogni **entità** diventa una relazione (tabella).
* Ogni **attributo** di un’entità diventa un attributo della relazione (tabella), cioè il nome di una colonna della tabella. Ogni attributo della relazione (tabella) eredita le caratteristiche dell’attributo dell’entità da cui deriva.
* L’**identificatore univoco** di un’entità diventa la chiave primaria della relazione (tabella) derivata.
* La relazione **uno a uno** diventa un’unica relazione (tabella) che contiene gli attributi della prima e della seconda entità, salvo alcune eccezioni.
* La relazione **uno a molti** viene rappresentata aggiungendo agli attributi dell’entità che svolge il ruolo *a molti* la chiave primaria dell’entità che svolge il ruolo *a uno* nella relazione. Questo identificatore, che prende il nome di **chiave esterna** dell'entità associata, è costituito dall’insieme di attributi che compongono la chiave dell’entità *a uno* della relazione. Gli eventuali attributi della relazione vengono inseriti nella relazione (tabella) che rappresenta l’entità *a molti*, assieme alla chiave esterna.
<ex>
Consideriamo due entità: *Studente* e *Classe*.
*Studente* *(Matricola, Nome, Cognome)*
*Classe* *(CodiceClasse, Anno, Sezione)*
La relazione **uno a molti** tra *Studente* e *Classe* può essere rappresentata aggiungendo agli attributi dell’entità *Studente* la chiave primaria dell’entità *Class* come chiave esterna.
*Studente* *(Matricola, Nome, Cognome, CodiceClasse)*
</ex>
* La relazione **molti a molti** diventa una terza relazione (tabella) composta dagli attributi chiave delle due entità e dagli eventuali attributi della relazione. La chiave della nuova relazione è, generalmente, formata dall’insieme di attributi che compongono le chiavi delle due entità, oltre agli eventuali attributi della relazione necessari a garantire l’unicità delle *n*\-uple nella relazione (tabella) ottenuta.
<ex>
Consideriamo due entità: *Studente* e *Corso*.
*Studente* *(Matricola, Nome, Cognome)*
*Corso* *(CodiceCorso, Titolo, Crediti)*
La relazione **molti a molti** tra *Studente* e *Corso* può essere rappresentata aggiungendo una terza relazione (tabella) che contiene le chiavi primarie delle due entità come chiavi esterne.
*StudenteCorso* *(Matricola, CodiceCorso, DataIscrizione)*
Ogni istanza di questa nuova tabella rappresenterà che lo studente identificato da *Matricola* frequenta il corso *CodiceCorso* dal giorno *DataIscrizione*
</ex>
La **chiave esterna** (**FK**, foreign key) è un attributo o un insieme di attributi di una tabella che identifica univocamente una riga in un’altra tabella.
La struttura delle relazioni viene rappresentata mediante il corrispondente **schema**, facendo seguire al nome della tabella, tra parentesi tonde, l’elenco dei campi corrispondenti agli attributi separati da virgola. Gli attributi sottolineati indicano la chiave primaria della tabella, mentre la chiave esterna viene evidenziata in corsivo (o, se fatto a mano, sottolineato con una linea ondulata).