Questo sito utilizza cookie per raccogliere dati statistici.
Privacy Policy
## Approfondimento sull'Apprendimento Supervisionato
### Cos'è l'apprendimento supervisionato?
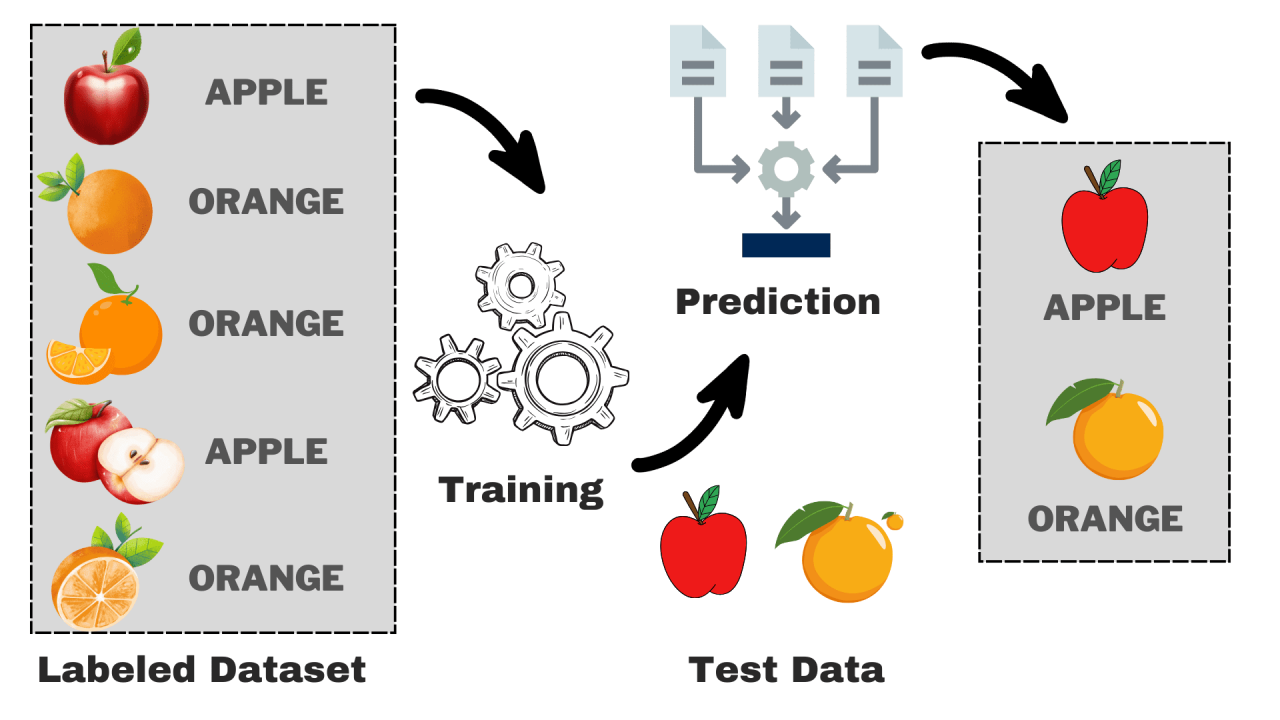
L'apprendimento supervisionato è un approccio del machine learning in cui un algoritmo viene addestrato su un set di dati etichettato. Ogni esempio nel set di addestramento è composto da un input e un output corrispondente, che l'algoritmo utilizza per imparare a mappare l'input all'output. L'obiettivo è costruire un modello capace di fare previsioni accurate su dati nuovi non etichettati.
**Esempi di applicazioni**:
- **Classificazione**: Identificare se un'e-mail è spam o non spam.
- **Regressione**: Prevedere il prezzo di una casa basandosi su caratteristiche come dimensioni e posizione.
### Come funziona l'apprendimento supervisionato?
Il processo dell'apprendimento supervisionato può essere riassunto nei seguenti passaggi:
1. **Raccolta dei dati**: Si raccolgono dati etichettati che rappresentano il problema da risolvere.
2. **Preprocessing dei dati**: I dati vengono preparati, puliti e trasformati in un formato utilizzabile dall'algoritmo.
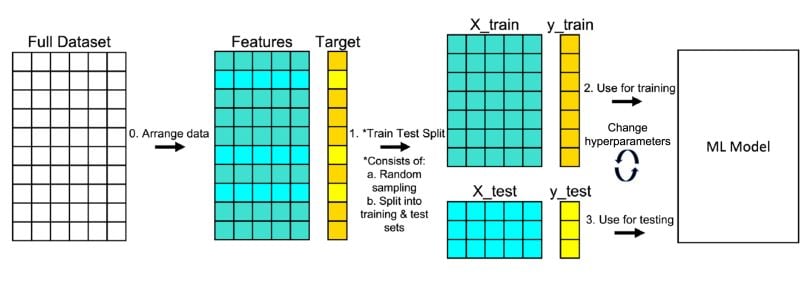
3. **Divisione dei dati (Train-test split)**: I dati vengono divisi in due set: il set di addestramento (training set) e il set di test (test set). Tipicamente, il set di addestramento rappresenta il 70-80% dei dati, mentre il set di test rappresenta il 20-30%.
4. **Addestramento del modello**: L'algoritmo elabora il set di addestramento per apprendere la mappatura tra input e output.
5. **Validazione e test**: Il modello viene testato sul set di test per valutare le sue prestazioni e generalizzazione.
6. **Miglioramento del modello**: Se necessario, si ottimizzano i parametri del modello o si adotta un altro algoritmo per migliorare le prestazioni.
### Suddivisione dei dati per l'addestramento e la valutazione
Quando si costruisce un modello di machine learning, è fondamentale dividere il dataset in due parti: una parte viene utilizzata per addestrare il modello e un'altra per testarlo. Questo permette di verificare come il modello, una volta addestrato, si comporta su dati che **non ha mai visto prima**. In questo modo, possiamo essere sicuri che non stia solo "memorizzando" i dati di partenza, ma che stia davvero imparando a fare previsioni utili.
La parte dedicata all'addestramento è quella su cui l'algoritmo impara a individuare le relazioni tra input e output, mentre quella di test è usata per vedere se le previsioni fatte sono corrette anche per dati nuovi. Solitamente, si riserva circa il 70-80% del dataset per l'addestramento e il resto per il test.