Questo sito utilizza cookie per raccogliere dati statistici.
Privacy Policy
# Introduzione al Machine Learning
## Cos'è il Machine Learning?
Il machine learning (apprendimento automatico) è un ramo dell'intelligenza artificiale che permette ai computer di apprendere da dati e migliorare le proprie prestazioni nel tempo senza essere esplicitamente programmati per svolgere un compito specifico. In altre parole, invece di scrivere manualmente tutte le regole per risolvere un problema, i programmatori forniscono al sistema un set di dati, e il sistema stesso costruisce un modello che apprende e prende decisioni basate su tali dati.
## Come funziona il Machine Learning?
Il machine learning si basa su algoritmi che analizzano i dati in ingresso, individuano schemi e relazioni, e utilizzano queste informazioni per costruire un modello predittivo o descrittivo. Il modello risultante può poi essere usato per prendere decisioni o fare previsioni su nuovi dati.
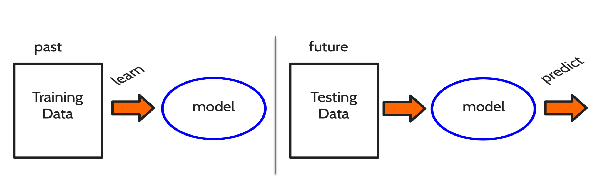
**Schema generale di funzionamento**:
1. **Raccolta dei dati**: il sistema necessita di una grande quantità di dati pertinenti per imparare.
2. **Addestramento del modello**: l'algoritmo elabora i dati e cerca schemi nascosti o correlazioni.
3. **Creazione del modello**: l'algoritmo genera un modello che può fare previsioni o classificazioni basate sui dati.
4. **Validazione e test**: il modello viene testato su dati non visti prima per valutare la sua capacità di generalizzare correttamente.
5. **Implementazione e ottimizzazione**: il modello viene messo in uso e ottimizzato in base al feedback e a nuovi dati.
**Esempio pratico**:
Consideriamo il caso di un sistema di raccomandazione per film, come quelli utilizzati dai servizi di streaming. Invece di programmare manualmente tutte le regole per decidere quale film consigliare, un sistema di machine learning può analizzare le preferenze passate degli utenti e identificare schemi che suggeriscono quali film potrebbero piacere a un utente specifico.
## Differenza tra programmazione tradizionale e Machine Learning
Nella programmazione tradizionale, un programmatore deve creare ogni regola per far funzionare un algoritmo. Invece, con il machine learning, si forniscono al computer esempi concreti, e l'algoritmo apprende automaticamente le regole e le relazioni a partire dai dati. Questo approccio è particolarmente utile per compiti complessi dove le regole non sono facilmente definibili.
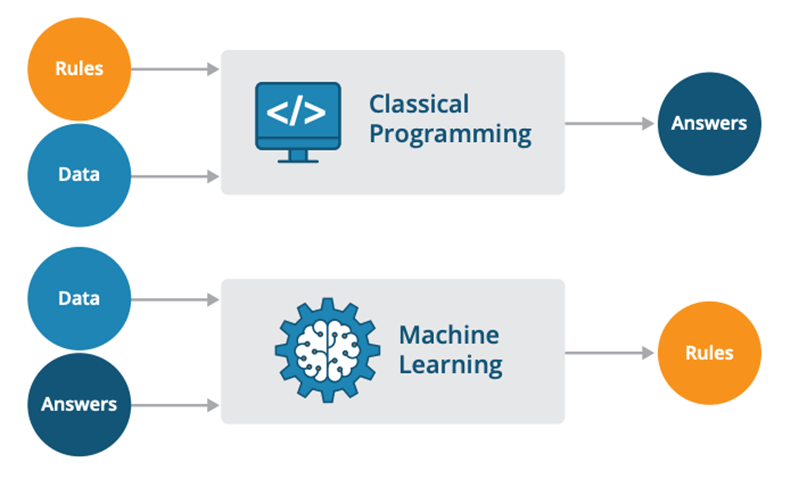
**Esempio di differenza**:
- **Programmazione tradizionale**: un programmatore scrive un codice per identificare manualmente una mela in un'immagine basandosi su caratteristiche come colore, forma e dimensioni.
- **Machine Learning**: l'algoritmo analizza migliaia di immagini di mele e non-mele, imparando a riconoscere da solo le caratteristiche comuni che definiscono una mela.
# Tipi di Machine Learning
Il machine learning si suddivide in diverse categorie in base al modo in cui gli algoritmi apprendono dai dati e risolvono i problemi. Le tre categorie principali sono: apprendimento supervisionato, apprendimento non supervisionato e apprendimento per rinforzo. Ognuna di queste categorie ha applicazioni, vantaggi e limiti specifici.
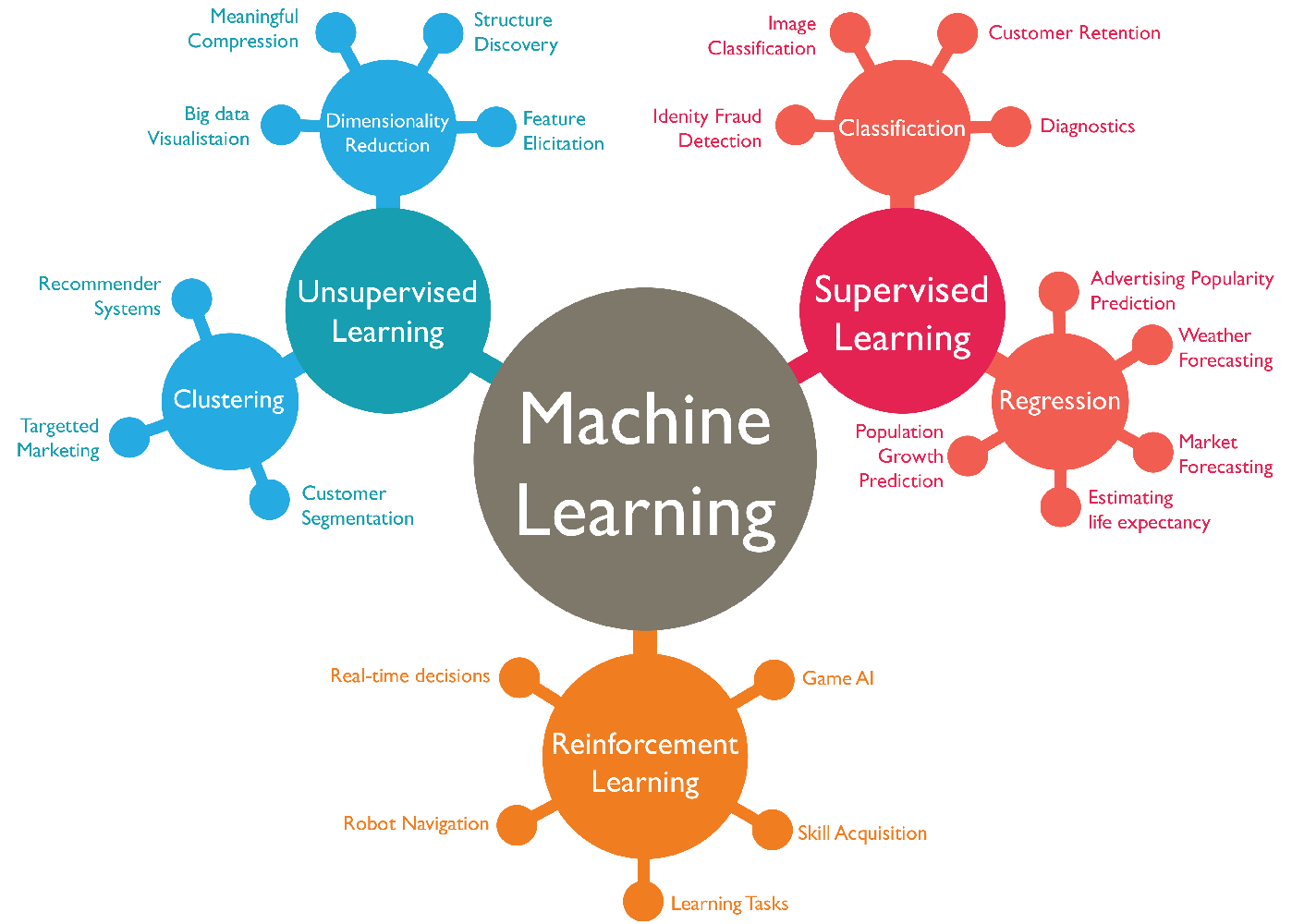
## Apprendimento supervisionato (Supervised Learning)
Nell'apprendimento supervisionato, l'algoritmo viene addestrato utilizzando un set di dati etichettato, in cui ogni esempio è accompagnato dall'output corretto. Durante l'addestramento, l'algoritmo cerca di imparare una funzione che mappa gli input agli output corretti, in modo da poter fare previsioni accurate su nuovi dati non visti prima.
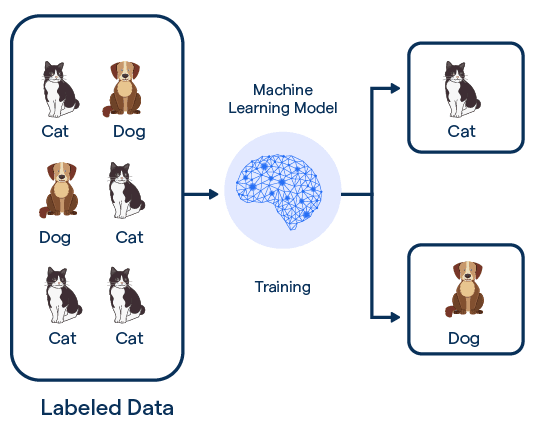
**Esempi di applicazioni**:
- **Classificazione delle immagini**: Identificare se un'immagine contiene un gatto o un cane.
- **Previsioni**: Stimare il valore di una casa in base a caratteristiche come la posizione, la metratura e il numero di stanze.
**Funzionamento**:
L'algoritmo confronta le sue previsioni con l'output reale e aggiorna i suoi parametri per minimizzare l'errore. Questo processo continua finché il modello non raggiunge un livello di accuratezza soddisfacente.
**Esempio pratico**:
Un sistema di riconoscimento di e-mail spam viene addestrato con un set di dati composto da e-mail già etichettate come "spam" o "non spam". L'algoritmo impara a identificare le caratteristiche comuni delle e-mail spam e usa questa conoscenza per classificare nuove e-mail.
**Vantaggi**:
- Elevata precisione con dati etichettati.
- Adatto per problemi ben definiti.
**Limiti**:
- Necessità di grandi quantità di dati etichettati.
- Rischio di overfitting, ossia quando il modello impara troppo bene i dati di addestramento e non generalizza sui nuovi dati.
## Apprendimento non supervisionato (Unsupervised Learning)
Nell'apprendimento non supervisionato, l'algoritmo lavora con dati non etichettati e cerca di scoprire autonomamente schemi o strutture nei dati. A differenza dell'apprendimento supervisionato, non vi è un output specifico associato agli input durante l'addestramento.
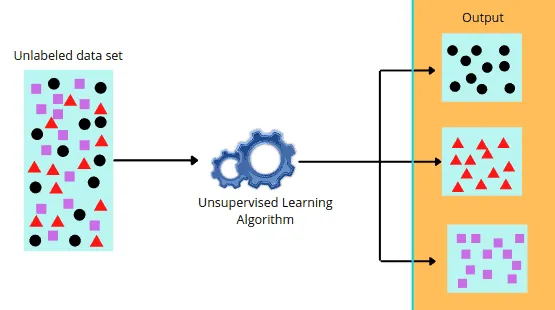
**Esempi di applicazioni**:
- **Clustering**: Raggruppare i clienti in base a comportamenti simili per strategie di marketing mirate.
- **Rilevamento di anomalie**: Identificare transazioni bancarie sospette.
- **Riduzione della dimensionalità**: Ridurre il numero di variabili per semplificare l'analisi dei dati.
**Funzionamento**:
L'algoritmo esplora i dati e identifica relazioni e pattern nascosti. Ad esempio, un algoritmo di clustering come il K-Means suddivide i dati in gruppi (cluster) basati sulla somiglianza tra gli elementi.
**Esempio pratico**:
Un'azienda di e-commerce può utilizzare l'apprendimento non supervisionato per raggruppare i propri clienti in base ai loro acquisti e abitudini di navigazione, in modo da personalizzare le raccomandazioni dei prodotti.
**Vantaggi**:
- Scopre relazioni e pattern che non sono evidenti a priori.
- Non richiede dati etichettati, rendendolo utile per esplorazioni iniziali dei dati.
**Limiti**:
- La valutazione del risultato è più difficile, poiché non c'è un output di riferimento.
- Gli algoritmi possono identificare pattern irrilevanti o difficili da interpretare.
## Apprendimento per rinforzo (Reinforcement Learning)
L'apprendimento per rinforzo è un tipo di machine learning in cui un agente interagisce con un ambiente, prende decisioni e riceve feedback sotto forma di ricompense o penalità. L'obiettivo dell'agente è massimizzare la ricompensa complessiva attraverso un processo di tentativi ed errori.
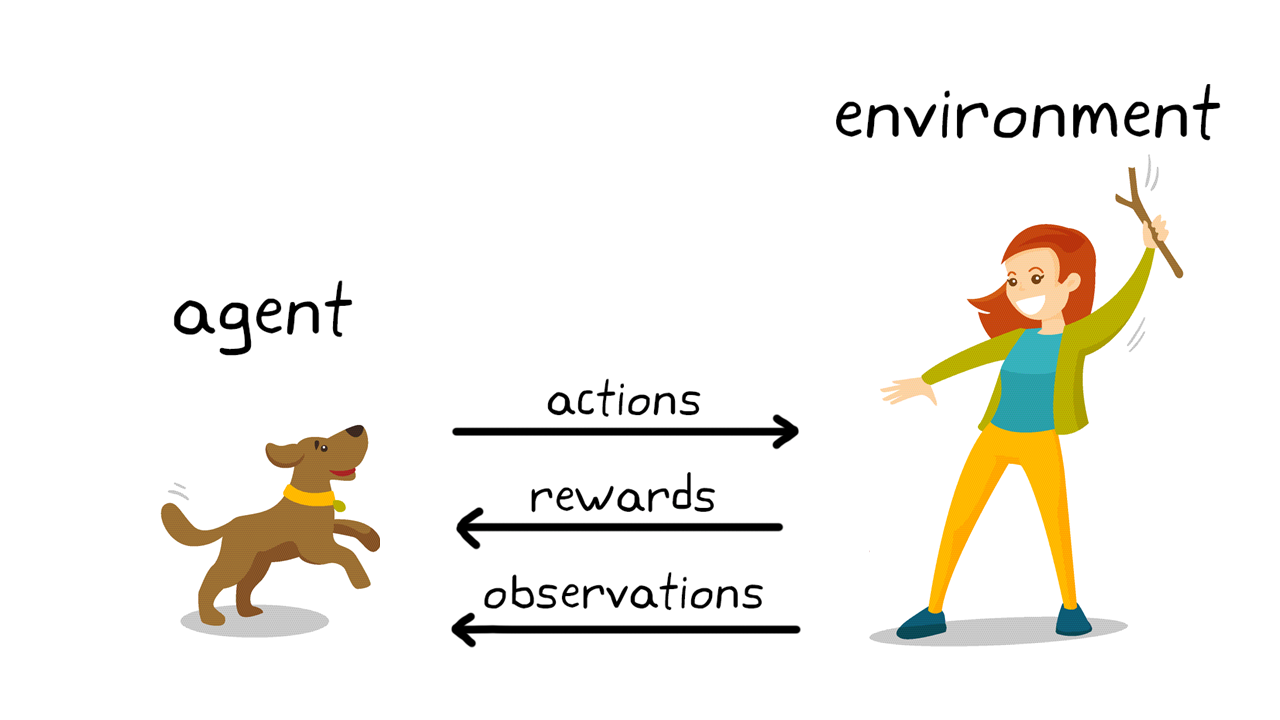
**Esempi di applicazioni**:
- **Giochi**: Algoritmi che apprendono a giocare a scacchi o a Go meglio degli esseri umani (come AlphaGo di DeepMind).
- **Robotica**: Addestrare robot a compiere azioni complesse, come il movimento o la manipolazione di oggetti.
- **Sistemi di raccomandazione**: Ottimizzare le interazioni con l'utente per migliorare l'engagement.
**Funzionamento**:
L'agente apprende tramite un ciclo di interazione:
1. Osserva lo stato attuale dell'ambiente.
2. Sceglie un'azione in base a una strategia (policy).
3. Riceve un feedback dall'ambiente (ricompensa o penalità).
4. Aggiorna la strategia per migliorare le future azioni.
**Esempio pratico**:
Immagina un robot in un labirinto che deve trovare l'uscita. Il robot esplora i percorsi e riceve una ricompensa positiva quando si avvicina all'uscita e una penalità quando si muove in una direzione sbagliata. Nel tempo, impara quali percorsi sono più efficaci per raggiungere l'obiettivo.
**Vantaggi**:
- Efficace per problemi complessi dove non è possibile definire tutte le regole a priori.
- L'agente può adattarsi e migliorare continuamente in base al feedback ricevuto.
**Limiti**:
- Richiede una grande quantità di iterazioni e può essere computazionalmente intensivo.
- Se mal progettato, può convergere su soluzioni subottimali.
## Confronto tra i tipi di machine learning
- **Apprendimento supervisionato**: Adatto a problemi con output ben definiti e dati etichettati. Ideale per classificazione e regressione.
- **Apprendimento non supervisionato**: Utilizzato per esplorare i dati senza output predefiniti. Utile per scoprire schemi nascosti e fare clustering.
- **Apprendimento per rinforzo**: Perfetto per situazioni dinamiche in cui un agente deve prendere decisioni basate su feedback continui.