Questo sito utilizza cookie per raccogliere dati statistici.
Privacy Policy
### Apprendimento per Rinforzo
### Cos'è l'apprendimento per rinforzo?
L'apprendimento per rinforzo è un tipo di machine learning in cui un agente apprende a compiere azioni in un ambiente per massimizzare una ricompensa cumulativa. L'agente interagisce con l'ambiente in modo iterativo, prendendo decisioni e ricevendo feedback sotto forma di ricompense o penalità. L'obiettivo dell'agente è trovare una strategia ottimale (policy) che gli permetta di massimizzare la somma delle ricompense a lungo termine.
**Esempi di applicazioni**:
- **Giochi**: Algoritmi che giocano a scacchi, Go o videogiochi come quelli sviluppati con l'intelligenza artificiale di DeepMind.
- **Robotica**: Addestrare robot per eseguire compiti complessi come camminare, afferrare oggetti o navigare in spazi sconosciuti.
- **Sistemi di raccomandazione adattivi**: Algoritmi che apprendono a suggerire contenuti agli utenti in base alle loro interazioni passate.
### Come funziona l'apprendimento per rinforzo?
Il processo di apprendimento per rinforzo si basa su un ciclo di interazione tra l'agente e l'ambiente. Durante questo ciclo, l'agente esegue azioni, osserva lo stato dell'ambiente e riceve una ricompensa. Utilizzando queste informazioni, l'agente aggiorna la sua strategia per migliorare le decisioni future.
**Componenti principali**:
- **Agente**: L'entità che prende le decisioni.
- **Ambiente**: Il contesto con cui l'agente interagisce.
- **Stato**: Una rappresentazione della situazione attuale dell'ambiente.
- **Azione**: La scelta che l'agente può compiere in un dato stato.
- **Ricompensa**: Il feedback immediato ricevuto dopo aver eseguito un'azione.
- **Policy**: La strategia che l'agente segue per decidere le azioni.
- **Funzione di valore**: Una stima del valore a lungo termine di uno stato, data una policy.
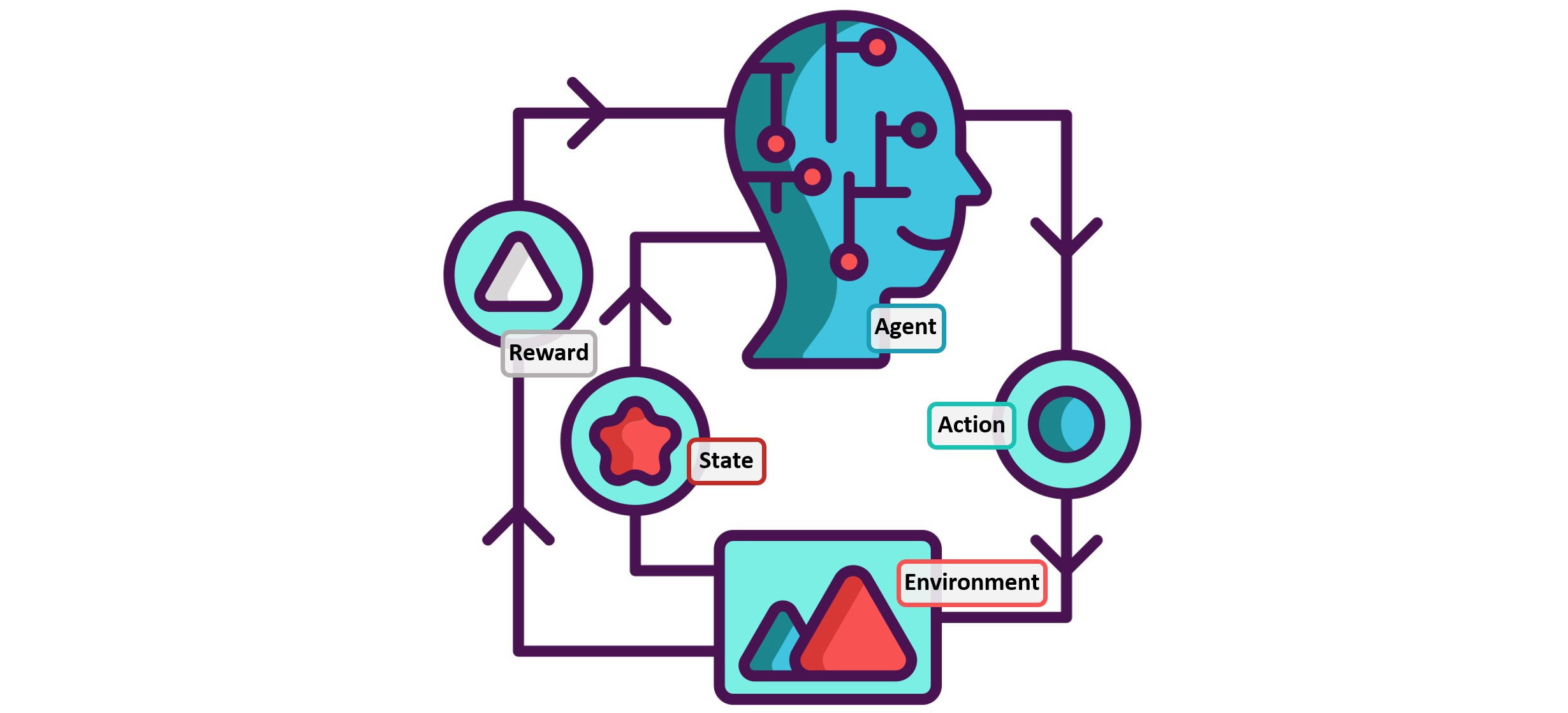
**Schema del processo**:
1. L'agente osserva lo stato attuale dell'ambiente.
2. L'agente sceglie un'azione basandosi sulla policy corrente.
3. L'azione modifica l'ambiente e l'agente riceve una ricompensa.
4. L'agente aggiorna la policy per migliorare le decisioni future basandosi sulla ricompensa e sul nuovo stato osservato.
5. Il processo si ripete finché l'agente non converge su una policy ottimale.
### Tipologie di apprendimento per rinforzo
- **Apprendimento basato su modelli**: L'agente ha una rappresentazione del modello dell'ambiente e lo utilizza per pianificare le azioni.
- **Apprendimento senza modelli**: L'agente apprende direttamente dall'interazione con l'ambiente, senza una rappresentazione esplicita del modello.
**Algoritmi noti**:
- **Q-Learning**: Un algoritmo di apprendimento senza modelli che cerca di apprendere una funzione di valore ottimale utilizzando un approccio basato su tabelle.
- **Deep Q-Networks (DQN)**: Una versione avanzata del Q-Learning che utilizza reti neurali profonde per approssimare la funzione di valore, rendendolo adatto per ambienti complessi e continui.
- **Policy Gradient**: Una famiglia di algoritmi che apprende direttamente la policy ottimale, aggiornandola gradualmente in base alle ricompense ricevute.
### Esempio pratico di apprendimento per rinforzo: Un robot in un labirinto
Immagina un robot che deve imparare a trovare l'uscita di un labirinto. Ogni volta che il robot si muove, riceve una ricompensa positiva se si avvicina all'uscita e una penalità se si muove verso un vicolo cieco o si allontana. All'inizio, il robot esplora casualmente il labirinto, ma col passare del tempo, memorizza le azioni che portano a una ricompensa maggiore e le utilizza per trovare la strada ottimale verso l'uscita.
**Vantaggi**:
- **Adattabilità**: L'agente può adattarsi a nuove condizioni e migliorare le prestazioni con l'esperienza.
- **Applicabilità a problemi complessi**: È utilizzabile per problemi dove è difficile definire regole esplicite o modelli deterministici.
**Sfide**:
- **Esplorazione vs. sfruttamento**: L'agente deve bilanciare l'esplorazione di nuove azioni con lo sfruttamento delle azioni note che garantiscono ricompense.
- **Computazionalmente intensivo**: Richiede un gran numero di iterazioni per apprendere una policy efficace, specialmente in ambienti complessi.
- **Stabilità e convergenza**: Garantire la stabilità e la convergenza può essere difficile, specialmente con algoritmi che utilizzano reti neurali.